Clickhouse and the open source modern data stack

What is Clickhouse?
Clickhouse is an open-source (24.9k ⭐) “column-oriented” database. Column-oriented (or “columnar”), refers to how data is organized in the database. Here’s a good comparison of “row-oriented” vs. “column-oriented” databases. Columnar databases are faster than their row-oriented counterparts for analytical queries (e.g. counting the # of events per day over billions of events). Clickhouse is particularly fast.
Clickhouse was open sourced (Apache 2) in June 2016. Clickhouse, Inc. formed a company around the technology in 2021 and raised $250M in October 2021 to build a cloud product for Clickhouse. Altinity is the OG in Clickhouse cloud hosting and we can’t recommend them enough. It will be interesting to watch what cloud hosting products are built around Clickhouse as the adoption picks up.
We choose Clickhouse when building Luabase because of its speed and have grown to ♥️ it. Here’s a public notebook with all the data and SQL we cover below.
Who’s using it?
Clickhouse has been used at companies like Uber, Comcast, eBay, and Cisco for years, mostly for log analytics. We’re now seeing startups (e.g. Tinybird, Posthog, Logtail) adopting Clickhouse in their product because it’s open source, has amazing performance, and doesn’t tie you to an insanely expensive cloud service (looking at you BigQuery). Due to the ubiquity of SQL, it’s also easier to find developers to work on the product and integrate it with other tools (e.g. Metabase). We choose Clickhouse at Luabase for these same reasons and think it’ll become the de facto choice when you need an open source, blazing fast database.
Prerequisites
The rest of this post won’t make much sense if you don’t know SQL. I recommend DataCamp if you’re interested in learning. If you want to run some of the code yourself, set up Clickhouse on your machine. We’ve also loaded the data to Luabase.
Show me some code
Many people have written a good deal about Clickhouse’s performance on billions of rows of data, so we’re going to instead focus on some of the features that make it good for analytics, specifically:
- Getting data into Clickhouse
- Standard SQL goodness
- Filtering, grouping, and sorting data
- Manipulating data
- Date functions
- Some not-so-standard SQL functions
- Progressively defining columns
- Ability to pivot data
- JSON functions
- The open-source modern data stack
- Getting data out of Clickhouse
Getting data into Clickhouse
This is a strong point of Clickhouse. It provides many ways to get data into it without adding another tool to your stack. The simplest import path is hitting a CSV file (or even a Google Sheet) that’s publicly available on the internet. This won’t work for “big data”, but it’s a good way to test the technology out.
If you already have data in Postgres or MySQL, Clickhouse can materialize data from an entire database or import data based on a SQL statement against the source database.
For simplicity, we downloaded a CSV of all HackerNews posts that mention SQL and loaded it to Google Cloud Storage. You can download the file here or query it in Clickhouse like this:
with hn as (
select *
from
url('https://storage.googleapis.com/luabase-public/hn.csv', CSVWithNames)
)
select
*
from hn
limit 5
format Vertical
This is great for getting a quick peak at the data, but to avoid importing the data every time we want to run a query we’ll store it in a table. Here’s a create table for it:
CREATE DATABASE hn
CREATE TABLE hn.content
(
`title` Nullable(String),
`url` Nullable(String),
`text` Nullable(String),
`dead` Nullable(Bool),
`by` String,
`score` Nullable(Float64),
`time` Nullable(Float64),
`timestamp` DateTime,
`type` Nullable(String),
`id` Float64,
`parent` Nullable(Float64),
`descendants` Nullable(Float64),
`ranking` Nullable(String),
INDEX hn_content_title_idx `title` TYPE bloom_filter GRANULARITY 1,
INDEX hn_content_type_idx `type` TYPE bloom_filter GRANULARITY 1,
INDEX hn_content_score_idx `score` TYPE bloom_filter GRANULARITY 1
)
ENGINE = MergeTree()
PARTITION BY (toYYYYMM(`timestamp`))
PRIMARY KEY (`id`, `by`)
ORDER BY (`id`, `by`)
SETTINGS index_granularity = 8192
You can then insert the data.
insert into hn.content
select *
from (
select *
from
url('https://storage.googleapis.com/luabase-public/hn.csv', CSVWithNames)
) as hn
If you want to skip the steps above, follow along in Luabase instead.
Standard SQL goodness
Filtering, grouping, sorting
You can do all the standard stuff you’d expect with SQL in Clickhouse. For example, let’s get the top 100 posts (by “score”) that include Postgres in the title
select *
from hn.content as c
where c.title ilike '%postgres%'
order by c.score desc
limit 100
Or a sum of all mentions for Postgres, MySQL, BigQuery, and Clickhouse by month
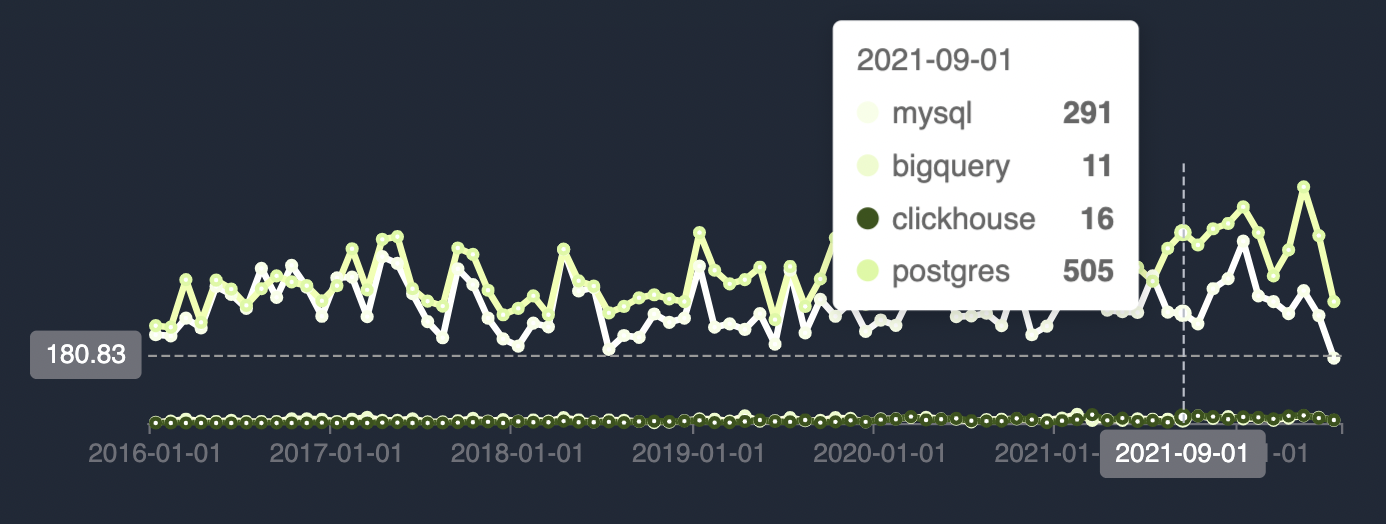
with flavor as (
select
"timestamp",
date_trunc('month', "timestamp") as content_month,
c."title",
c."text",
c."url",
(
case
when
c."text" ilike '%postgres%' or
c."title" ilike '%postgres%' then 1
else 0
end)
as "postgres",
(
case
when
c."text" ilike '%mysql%' or
c."title" ilike '%mysql%' then 1
else 0
end)
as "mysql",
(
case
when
c."text" ilike '%bigquery%' or
c."title" ilike '%bigquery%' then 1
else 0
end)
as "bigquery",
(
case
when
c."text" ilike '%clickhouse%' or
c."title" ilike '%clickhouse%' then 1
else 0
end)
as "clickhouse"
from hn."content" as c
)
select
content_month,
sum(postgres) as postgres,
sum(mysql) as mysql,
sum(bigquery) as bigquery,
sum(clickhouse) as clickhouse,
count() as "total"
from
flavor as f
group by content_month
order by content_month asc
-- limit 200
Just BigQuery and Clickhouse
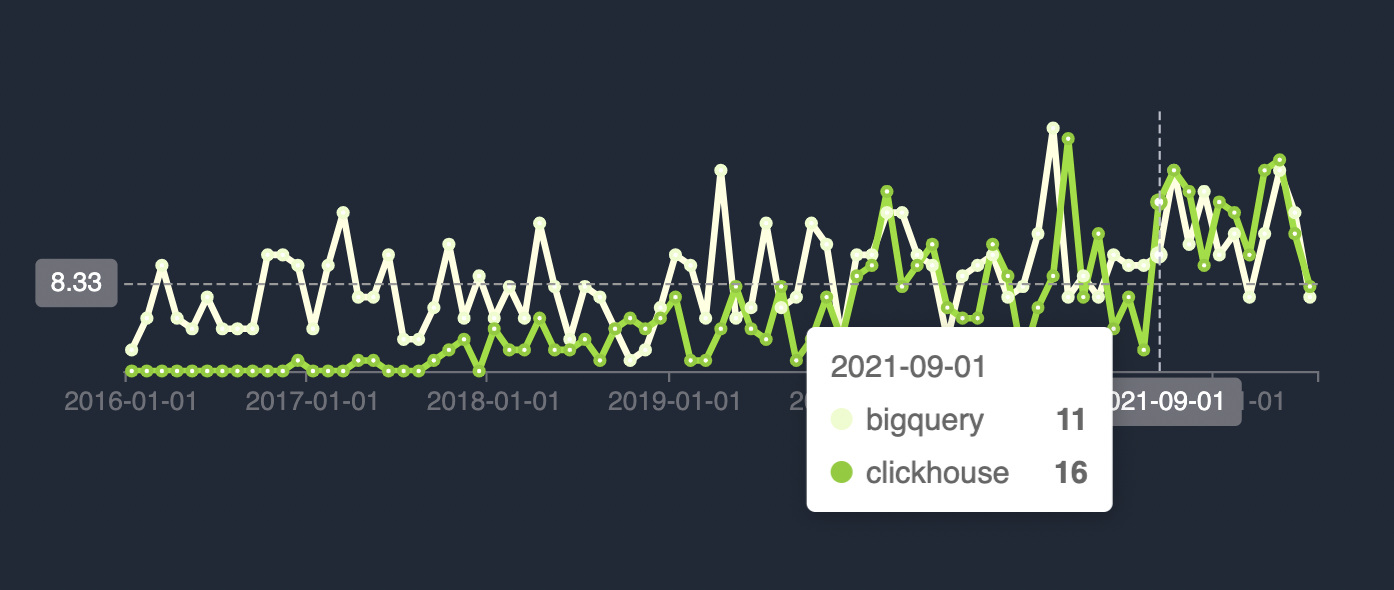
Some not-so-standard SQL functions
There are a few additions to Clickhouse’s SQL dialect that are particularly useful and not commonly found in other dialects:
Progressively defining columns
You can use a column you alias (as) in the definition of a subsequent column
select
case when c.text ilike '%clickhouse%' then 1 else 0 end as contains_ch,
case when contains_ch = 1 and c.score > 10 then 1 else 0 end as contains_ch_high_score,
c.score,
substring(c.text, 1, 20) as substr_text
from hn."content" as c
order by contains_ch_high_score desc
limit 20
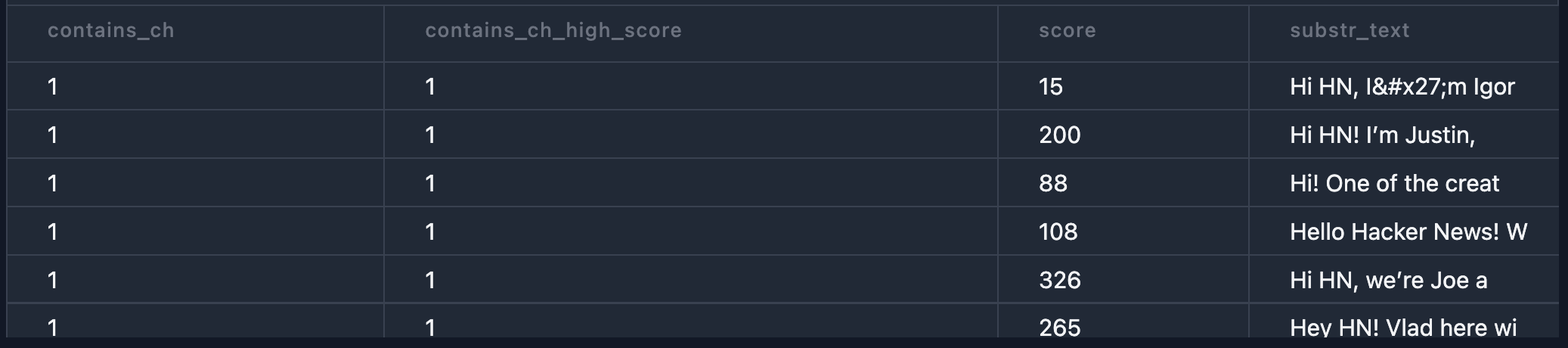
Pivoting data
You can pivot data wit sumMap (link)
with hn as (
select
date_trunc('month', "timestamp") as content_month,
c.score,
case
when
(c."text" ilike '%bigquery%' or
c."title" ilike '%bigquery%') and
(c."text" ilike '%clickhouse%' or
c."title" ilike '%clickhouse%') then 'both'
when
(c."text" ilike '%bigquery%' or
c."title" ilike '%bigquery%') then 'bq'
when
(c."text" ilike '%clickhouse%' or
c."title" ilike '%clickhouse%') then 'ch'
else 'neither'
end as "bq_or_ch"
from hn."content" as c
)
select
content_month,
sumMap(map(bq_or_ch, score)) as sum_map_bq_or_ch,
ifNull(sum_map_bq_or_ch['both'], 0) as both,
ifNull(sum_map_bq_or_ch['bq'], 0) as bq,
ifNull(sum_map_bq_or_ch['ch'], 0) as ch
from hn as c
group by content_month
order by content_month desc
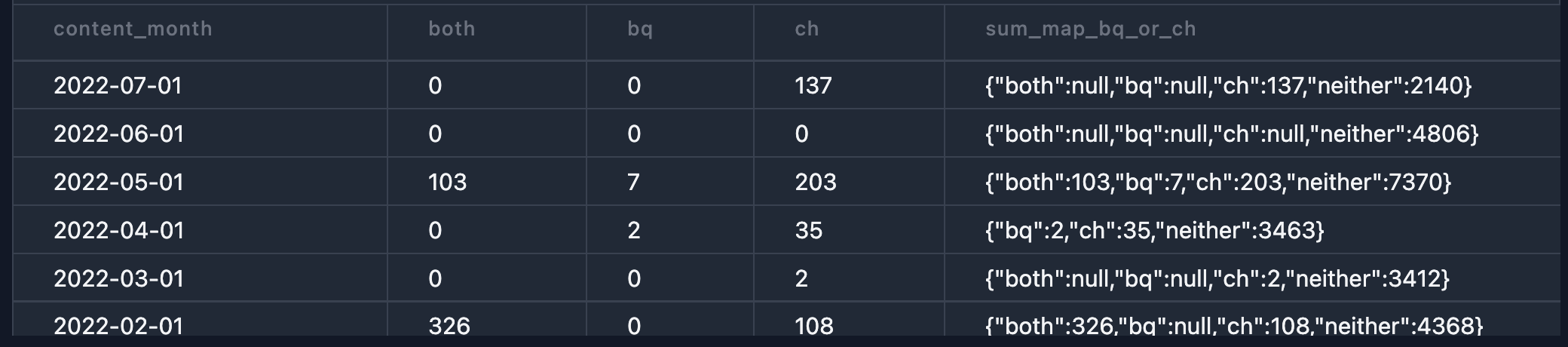
Clickhouse also has extensive support for handling JSON. Clickhouse released an experimental JSON column type in 22.3. It’s not at the level of JSON support in Postgres, but it’s on a path towards it.
The open-source modern data stack
Clickhouse seems cool, but how does it fit in with the rest of the tools we've all grown to love?
dbt
Clickhouse, Inc. recently accepted ownership of the dbt plugin for clickhouse. It doesn't have support for all the bells and whistles of clickhouse (e.g. Live Views and more advanced Table Engines), but they're moving fast to improve it.
ETL
Most of the big players (Fivetran, Airbyte, Rudderstack, etc.) have relatively limited support for Clickhouse today. Our pick: Airbyte. It supports Clickhouse as both a source and destination. It also has support for all the sources you'd expect and since its open source, fits nicely with the ethos of Clickhouse.
Business Intelligence
As in ETL, there's limited support for Clickhouse, but Metabase was one of the first to add support and is also open source. Other more established players like ThoughSpot and Looker are working to add Clickhouse as customers demand it.
Your open-source data stack
- ETL your data with Airbyte
- Clickhouse as your data warehouse
- dbt as your modeling layer
- Metabase for business intelligence and dashboards
Getting data out of Clickhouse
Clickhouse offers many export formats including those you’d expect like JSON, CSV, Parquet, and Arrow. We’ve used them all at Luabase and they work just like you’d expect. There’s also built-in support for exporting to S3 or Google Cloud Storage.
The Ugly
Ok, Clickhouse is clearly amazing, but what aren't you telling me? This sounds too good to be true.
You're right. There are some rough edges you're going to need to deal with using Clickhouse. If you're used to just throwing BigQuery or Snowflake compute at your data engineering problems, you need to change your mindset when working with Clickhouse. It requires more thoughtful data modeling and more DevOps work than its commercial counterparts. JOIN's are also not nearly as performant as in other cloud data warehouses. There are features to overcome this weakness, but they require an amount of work you might not be willing to put in. If having a fully open source stack is paramount to your product and you're willing to put the work in, look no further than Clickhouse. But if you need a data warehouse that "just works", Clickhouse is not the best option. There are still too many rough edges to justify using it for basic analytics needs.